2021년 8월 즈음에 대한민국에서 IT로 가장 "핫"한 키워드는 바로 메타버스, AI를 말할 수 있을 것 같다.
어느 매체, 비즈니스 기획 회의, 전략회의 등 사람들이 만날 때 꼭 이야기되는 키워드이다. 이런 기술적인 부분이 이제는 우리 생활에 꼭 필요한 한 부분이라고 생각이 들고, 앞으로 우리 생활 행태도 바꿀 것이라 생각이 들긴 하는데, 과연 이런 기술을 이야기하는 우리 자신은 얼마나 알고 있을까. 그래서 먼저 AI (인공지능) 기술에 대해 조금씩 천천히 파해쳐 보려고 한다.
인공지능의 등장

우리는 지금 우리도 모르게 인공지능(AI)을 사용하고 있다. 가장 가깝게는 모바일 기기부터 자동차 자율주행, AI 상담원, AI 면접 등 근본적인 부분에서부터 서비스적인 측면까지 다양한 부분에서 AI 적용이 확대되고 있는 상황이다. 이렇게 우리의 생활 속에 알게 모르게 침투하고 있는 이 AI는 도대체 언제부터 연구가 시작되었을까? 아주 심플하게 생각해보면 가장 화두가 된 시기는 아마 알파고의 충격을 줬던 2016년 즈음 시기였을 것이다. 그리고 어떤 사람들은 인공지능이 그때부터 시작되었다고 이야기하기도 한다. 그런데 알다시피 이런 연구는 하루아침에 나오는 게 아니다. 적어도 몇 년에서 길게는 몇 백 년 전부터 시작하여 서서히 발전하다 어느 임계점이 터지는 시기에 그제야 우리에게 그 모습을 나타낸다. 인공지능도 마찬가지다. 사실 인공지능이 연구되기 시작한 시점은 1950년도 즈음이었다.
1957년에 처음으로 인공지능의 등장은 '퍼셉트론' 개념을 기반으로 개발이 진행되었다. 그렇지만 바로 이듬해인 1958년에 XOR 연산의 한계를 겪으면서 인공지능의 개발 시작이 되자마자 한계를 뛰어넘지 못한 1차 암흑기가 찾아왔다. 그렇지만 10년뒤 1968년에 이 한계를 뛰어넘은 NAND, AND, OR을 기반으로 '다층 퍼셉트론'의 등장으로 다시 기지개를 피나 했더니 다시 90년대 순환 신경망의 등장하기까지 2차 암흑기를 겪게 된다. 사실 암흑기는 겪기는 했지만 이 기간 동안 학자들의 연구는 지속적으로 진행이 되었고, 2010년 시기에 딥러닝이라는 개념이 등장하고, 신경망 은닉층에서의 문제였던 Gradient Vanishing 문제를 ReLu, Leaky ReLu와 같은 활성화 함수로 해결할 수 있음에 따라 인공지능의 발전은 점점 가속을 붙게 되었다.
사람 같은데 사람이 아닌... 인공지능은 과연 무엇?

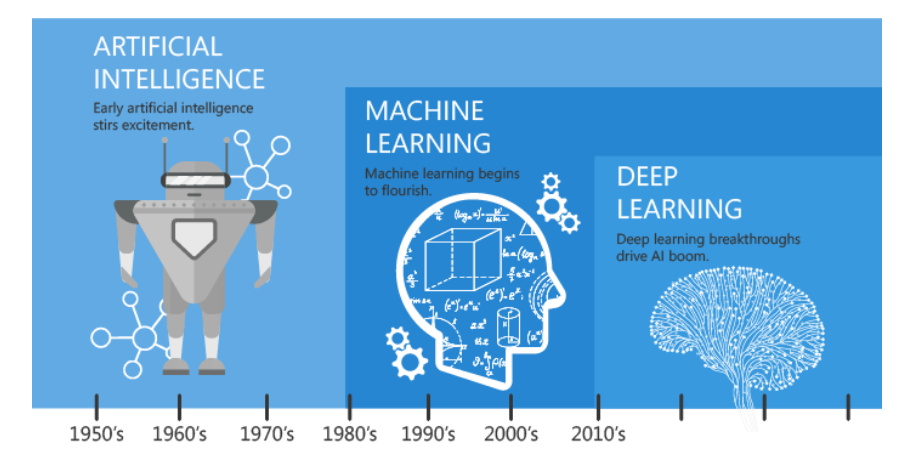
인공지능의 개념을 아주 간단히 이야기한다면 이렇게 이야기 할 수 있지 않을까. 인간의 지적 능력을 컴퓨터로 구현하는 기술. 좀 더 자세히 이야기한다면 인간의 신경망을 수학적 모델링하여 빅데이터 학습, 분석하여 인간과 같은 판별력을 얻을 수 있는 기술. 이렇게 인공지능을 정의 할 수 있다면 '머신러닝은 또 무엇이고, 딥러닝은 또 무엇인가'라는 의문을 가질 수가 있을 것이다. 범주를 따지자면 위 그림과 같이 '인공지능 > 머신러닝 > 딥러닝' 이런 포함 관계라고 말할 수 있을 것이다.
머신러닝은 '컴퓨터(기계)가 데이터를 통해 스스로 학습하여 예측, 판단을 제공하는 기술'이라고 정의를 할 수 있을 것이고, 딥러닝은 '사람과 같은 뉴런 모델, 알고리즘을 모방하여 적용, 스스로 진화하면서 학습하여 예측, 판단을 제공하는 기술'이라고 할 수 있을 것이다. 즉, 인공지능이 조금 넓은 범주, 딥러닝은 좀 더 세부적인 이야기를 한다고 보면 될 것이다.
인공지능 학습의 메커니즘, 퍼셉트론


앞에서 인공지능은 사람의 뇌구조와 비슷하게 진화 학습한다고 이야기했는데 실제로 인공지능의 학습은 어떻게 진행되는 것인가. 인공지능의 역사에 대해서 언급할 때 이야기했던 '퍼셉트론'의 피드 포워드 방식으로 인공지능은 학습을 진행한다.
사람의 뉴런 같은 경우에도 가지돌기에서 입력(Input)을 받고 그 입력을 신경 세포체, 핵에서 종합으로 합산하여 판단 후 축삭돌기를 통하여 자극을 다음 신경 세포체 또는 핵으로 출력(Output)을 전달한다. 마찬가지로 퍼셉트론 역시 입력(Input)으로 여러 데이터가 가중치를 기반으로 들어오게 되면 그 입력을 합산하고 데이터가 활성화 함수(Activation Function)를 통하여 출력(Output)을 할 것인지, 다음 뉴런으로 데이터를 전달할 것인지 결정하게 된다. 이러한 순차적인 방향으로 진행되는 메커니즘을 피드 포워드(Feed forward)라고 이야기한다.
이런 퍼셉트론 구조와 피드포워드 방식이 인공지능의 기본이기는 하지만 그 한계점이 존재하였고, 한계를 돌파하면서 진화하였는데 그에 대해서는 이후 포스트에서 좀 더 깊이 이야기해보고자 한다.
인공지능의 학습 방법, 지도, 비지도, 강화 학습

퍼셉트론과 피드 포워드 방식으로 인공지능 학습이 진행되기는 한데, 실질적으로 일반적인 사람이 어떤 판단을 할 경우에도 다양한 방식으로 생각하고, 그에 따라 예측하듯 인공지능 역시 하나의 방식으로만 사고를 하지는 않는다. 따라서 현재 일반적으로 인공지능 학습은 위 그림과 같이 3가지 방식, 지도 학습(Supervised Learning), 비지도 학습(Unsupervised Learning), 강화 학습(Reinforcement Learning)으로 구분하여 학습을 진행한다.
3가지 학습방법을 좀 더 살펴보면, 지도 학습(Supervised Learning)의 경우, 인공지능에 학습에 대한 목표를 제시하고, 목표 기반한 데이터를 판단하도록 훈련시키는 방법이다. 가령 인공지능 모델이 개의 모습, 이미지를 학습하기 원한다고 하면 다양한 개의 이미지를 인공지능에게 학습시키고, 이후 고양이와 개의 이미지를 주고서 판단을 해보라 하는 방식이다. 이 방식으로 사용은 데이터의 분류나 인과관계를 기반으로 하는 회귀 분석방식에 주로 사용된다.
비지도 학습 (Unsupervised Learning)의 경우, 지도 학습과는 다르게 학습에 대한 목표는 주어지지 않는다. 그 대신 다양한 데이터를 제시하고, 이 데이터가 어떤 것인지에 대한 판단을 스스로 하도록 맡기는 방법이라고 할 수 있다. 다양한 데이터를 기반으로 비슷한 데이터를 군집으로 구분해 가면서 학습을 하는 방법이라 보면 될 것이다. 이 방식은 주로 클러스터링(Clustering) 방식에서 주로 사용이 된다.
마지막으로 강화 학습(Reinforcement Learning)의 경우, 환경을 기반으로 입력(Input)을 학습하고, 이 입력을 기반한 행동에 대한 보상으로 학습을 하는 방식이다. 예를 들면 어떤 입력을 인공지능 모델이 받고서 행동을 했는데 이 모델은 이 행동이 옳은 것인지 그른 것인지 판단을 할 수 없다. 그렇지만 옳은 행동일 때 그에 따른 보상을 해주면 그에 대한 학습을 강화하고 그렇지 못한 경우 보상을 하지 않았을 때는 그 행동을 그른 것이라고 판단하는 것이다.
인공지능이라는 분야는 연구된 기간만 보더라도 상당히 진행되고, 깊이 들어가면 어려운 기술이다.
그렇지만 현재 우리에게 점점 더 다가오는 이상 더 이상 나 몰라라 할 수도 없는 기술이다.
그래서 아주 쉬운 개념에서부터 하나씩 접근해보고자 한다.
이 기본 개념을 기반으로 좀 더 세부적인 내용을 다음 포스트에서 이야기해보고자 한다.
※ 함께 보면 좋은 글
데이터 라벨링과 빅데이터, 인공지능
빅데이터, 인공지능과 같은 개념, 단어는 2020년을 살아가는 우리에게 있어서 당연한 것으로 생각하고 있다. 아니 오히려 모르면 이상한 취급을 당할지도 모른다. 그럼 다시, 인공지능과 빅데이
techness.tistory.com