빅데이터, 인공지능과 같은 개념, 단어는 2020년을 살아가는 우리에게 있어서 당연한 것으로 생각하고 있다. 아니 오히려 모르면 이상한 취급을 당할지도 모른다. 그럼 다시, 인공지능과 빅데이터를 쉽게 이야기하는 당신에게 묻겠다. '이것들은 무엇인가?' 이렇게 이야기하면 쉽게 대답을 하기가 힘들 것이다. 이는 우리가 쉽게 말하는 이 개념을 잘 모른다는 이야기가 아닌가 싶다. 어쩌면 이들의 기반인 데이터에 대해서도 잘 모를 수도 있다는 생각이 든다.
인공지능(AI)이 있기 위해서는 '잘 만들어진' 데이터가 필요하다.

아주 쉽게 예를 들어보자. 우리가 지식을 쌓고 학습을 하기 위해서는 다양한 자료를 기반으로 한 정보들을 보고 그것을 해석하고 어떠한 의미인지 분석하고 활용하고 사용하면서 내제화 시켜 우리의 능력을 향상시켜왔다. 이 예시를 그대로 인공지능에 대입해 보면 인공지능이 지식을 쌓고 학습하기 위해서는 다양한 자료를 기반으로 한 데이터들이 필요하다. 인공지능은 잘 만들어진 데이터를 100%로 신뢰하여 그대로 해석하고 의미를 분석하고 학습을 한다. 그리고 그 양이 많아지면서 그들의 지능은 고도화되는 것이다. 즉, 인공지능의 기반은 잘 만들어진 데이터라 할 수 있을 것이다.
많은 사람들은 여기서 오해하는 점이 있다. '많은' 데이터에만 주목을 하고 '잘 만들어진' 데이터에 대해서는 조금 소홀하게 생각한다는 것이다. 다시 말해 마치 많고 다양한 데이터가 있으면 무엇이든 될 것이라 생각하는 것 같다. 그렇지만 '잘 만들어진' 데이터가 선행되지 않는다면 많은 데이터들은 쓰레기가 될 가능성이 있다. 그래서 우리는 인공지능에 학습하기 전에 정제하고 인공지능이 잘 알아들을 수 있도록 라벨링이란 작업을 한다.
데이터 라벨링(Data Labeling)이란 무엇인가?

데이터 라벨링이란 개념을 정의하자면 이렇게 이야기 할 수 있을 것 같다. '인공지능(AI) 학습 데이터를 만들기 위해 원천 데이터에 값(라벨)을 붙이는 작업' 사실 이 정의가 개인적으로 정말 명확한게 아닌가 생각한다. 더도 덜도 말고 군더더기도 없는 설명인 것 같다. 어떻게 보면 이 데이터 라벨링(Data Labeling)이란 작업이 인공지능(AI) 전체에 있어서는 정말 중요한 개념이 아닌가 생각된다. 그렇지만 IT, 데이터를 다루는 업계에 있어서는 'AI 눈알 붙이기, IT업계의 막노동'이라는 인식이 더 큰 것이 사실이다. 왜냐하면 목표에 대해 데이터를 구축 설계 이후에는 단순작업이 많기 때문이다. (참고 : https://www.youtube.com/watch?v=WOmkHgtVabM)
그 어떤 단계보다 중요한 단계 '데이터 라벨링'

많은 사람들은 인공지능의 신경망(개념에 대해서는 추후 포스팅 할 예정)을 이야기하면서 마치 마법처럼 인공지능에 뭐든 데이터를 넣는다면 내가 모르는 인사이트(Insight)까지 내놓을 것이라 쉽게 생각한다. 물론 앞에서 이야기한 '잘 만들어진' 데이터를 기반으로 많은 데이터를 학습하고 최적화가 된다면 이상적으로는 내가 몰랐던 분석까지 내놓는 것이 맞다. 그렇지만 지금 상황에서는 인공지능을 학습하는 데이터를 인공지능 스스로가 선호하는 데이터를 보고 선별하여 학습하지는 못하기에 사람이 사용목적에 맞는 인공지능을 학습시키기 위해 데이터를 잘 만들어 주어야 한다. 다시 말해서 인공지능이라는 것은 사람처럼 스스로 모든 것을 할 수 없다.
인공지능이 등장하기 이전에 빅데이터를 기반으로 분석하고 예측하는 많은 전문가들이 한결 같이 이야기 하는 것은 분석, 예측하는 것보다 데이터 수집, 가공을 하는데 80% 이상의 시간을 보낸다는 것이다. 이는 다시 해석을 해보면 어떤 데이터를 수집해서 어떤 목적으로 가공하느냐에 따라 분석 결과, 예측에 상당한 영향을 미친다는 이야기이다. 업계에서는 상당히 부담스러운 그런 작업임에 불구하고 빅데이터, 인공지능(AI)에 있어서 정말 중요한 단계임은 부인할 수 없을 것 같다.
인공지능(AI) 학습 데이터의 구축 단계
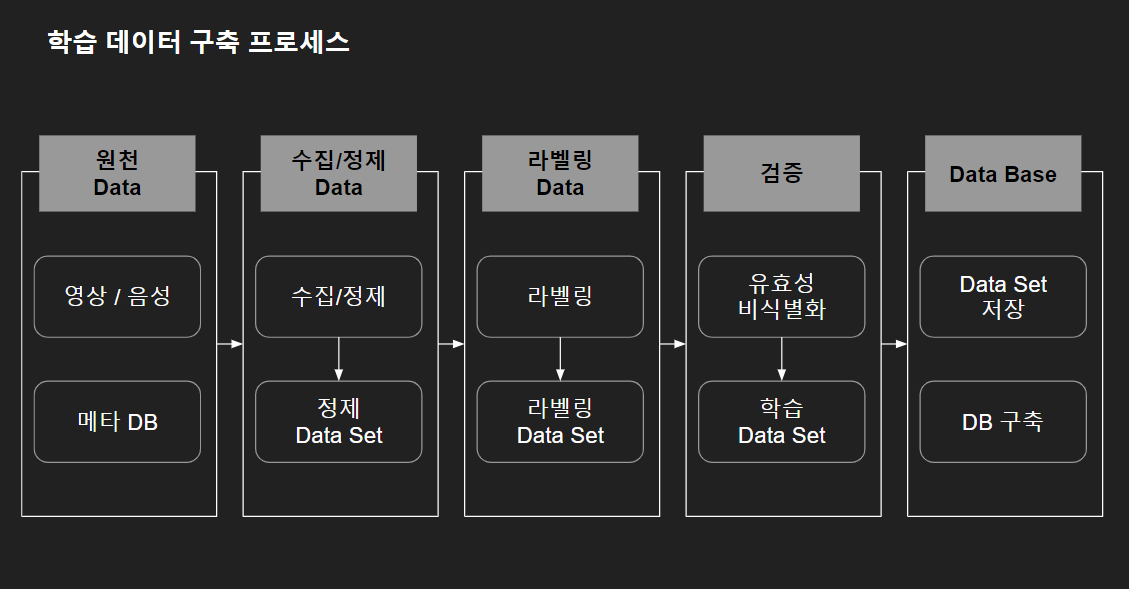
그럼 인공지능(AI) 학습을 위한 원석이라고 할 수 있는 데이터는 어떻게 만들어지는가. 아주 개념적으로 구분하자면 5단계로 진행되지 않는가 생각된다.
1단계 : 원천 데이터 수집. 데이터를 잘 만드는 게 중요하지만 사실 그보다 잘 만들 수 있는 데이터를 수집하는 게 사실 더 중요하고 어려운 부분이다. 많은 매체에서 우리는 데이터를 흘리고 다닌다, 이를 분석하면 된다 이야기 하지만 막상 데이터를 분석하고자 데이터 수집부터가 큰 허들이다. (데이터 수집 방법에 대해서는 추후 포스팅 예정) 그럼 데이터를 수집할 수 있는 데이터는 어떤 것이 있을까. 정형(텍스트) 데이터와 비정형(영상, 음성) 데이터로 크게 개념적으로 나눌 수 있을 것이다. 그리고 그에 대한 메타 데이터도 수집 대상이 될 수 있을 것이다. 주의할 점은 이 원천 데이터를 사용하기 전에는 반드시 저작권 문제, 보안(개인정보) 문제들을 사전에 해결해야 한다는 점이다.
2단계 : 데이터 수집/정제. 수집된 원천 데이터를 기반으로 실제 우리 목적에 맞은 인공지능을 학습시키기 위해서는 데이터를 목표와 기준에 맞는 선정을 하는 과정이 필요하다. 그 단계가 이 단계라 보면 될 것 같다. 아무리 많은 데이터가 있지만 그중에서 정말 도움이 될 만한 옥석 같은 데이터를 선정해서 학습하여야 인공지능의 성능을 높일 수 있을 것이다.
3단계 : 데이터 라벨링(Data Labeling). 지금까지 줄 곧 이야기했던 데이터 라벨링 단계이다. 학습 데이터 전체 구축 과정 중 가장 중요한 단계라 생각하여 많은 사람들이 데이터 구축보다 라벨링 이야기를 많이 하는 것 같다. 데이터 라벨링은 그럼 무엇이고, 어떻게 하는 것인가. 개념은 영상, 음성, 텍스트로 이루어진 데이터를 각 분류 기준에 맞게 잘 구분하여 이름을 짓고, 정리하는 것이라 생각하면 될 것이다. 그럼 '어떻게 하는 것인가.'라고 질문한다면 영상의 경우는 이미지 어노테이션(Image Annotation) 기법을 통하여 영상 분석을 하고 각 객체, 즉 부분에 대해 라벨링을 진행한다. 음성의 경우는 전사(transcription : 음성을 듣고 그대로 받아쓰기한 내용)를 기반으로 라벨링을 진행한다. 마지막으로 텍스트의 경우는 형태소 기반으로 분류 태그를 다는 형식으로 진행된다고 보면 된다.
4단계 : 데이터 검증. 실제로 라벨링 된 데이터가 있다고 한다면 바로 인공지능에 학습을 시켜 결과를 지켜볼 수도 있다.그렇지만 라벨링된 데이터가 정말 유효성이 있는 데이터인지, 개인정보와 같은 민감정보는 비식별화가 잘 되었는지에 대해 검증을 할 필요가 있다. 이렇게 검증 작업까지 순차적으로 진행되는 과정에서 5~10%가 마무리되면 인공지능에 지속적으로 학습시킨다고 한다.
5단계 : DB(Data Base) 구축. 인공지능이라는 것은 사람이 지속적으로 기계를 학습시키는 과정이라고 본다면 한 번의 학습에 모든 것을 만족시킬 수 없을 것이다. 그러므로 이런 학습 데이터는 추후를 대비해서라도 잘 저장하고 관리하는 것이 필요하다. 그러한 점에 있어서 학습에 사용된 데이터들은 어떤 형식으로든지 효율적인 방식으로 잘 저장 보관하도록 해야 할 것이다.
왜 데이터 라벨링에 주목하는가?

사실 전체 데이터 중 가장 중요한 부분이라면 당연히 이전부터 주목되어야 했던 것이 맞을 것이다. 그런데 왜 최근 들어 더 이야기가 나올까. 다른 많은 환경의 변화와 우리도 이 인공지능을 써야 할 때가 된 것이라는 이야기가 아닌가 하는 생각이다. 그런 환경이 된 상황에서 나오게 된 정부 정책이 데이터 라벨링(Data Labeling)의 중요성을 더 강조되고 있는 상황이다.
사실 우리뿐만이 아니라 이미 몇 년 앞서서는 미국, 유럽 등에서는 정부와 민간 협업 투자로 대규모 데이터 셋을 구성하여 공개하고 있다. 이런 측면에서 볼 때 우리의 데이터 생태계 환경 구축은 필요했던 것 중 하나는 아니었는가 하는 생각이다. 그렇지만 간과하지 말아야 될 것 중 하나가 이런 데이터 셋을 공공으로 구축한다고 모든 것이 해결되는 것이 아니라는 점이다. 꾸준히 데이터 사용에 대한 규제를 완화하여야 하고, 꾸준히 이를 기반으로 더 발전된 데이터 셋과 활용 서비스를 만들어 내야 한다는 것이 더 중요한 게 아닌가 하는 생각이다.
* 함께 보면 좋은 글
딥러닝, 신경망, 머신러닝 그리고 인공지능, AI
2021년 8월 즈음에 대한민국에서 IT로 가장 "핫"한 키워드는 바로 메타버스, AI를 말할 수 있을 것 같다. 어느 매체, 비즈니스 기획 회의, 전략회의 등 사람들이 만날 때 꼭 이야기되는 키워드이다.
techness.tistory.com